







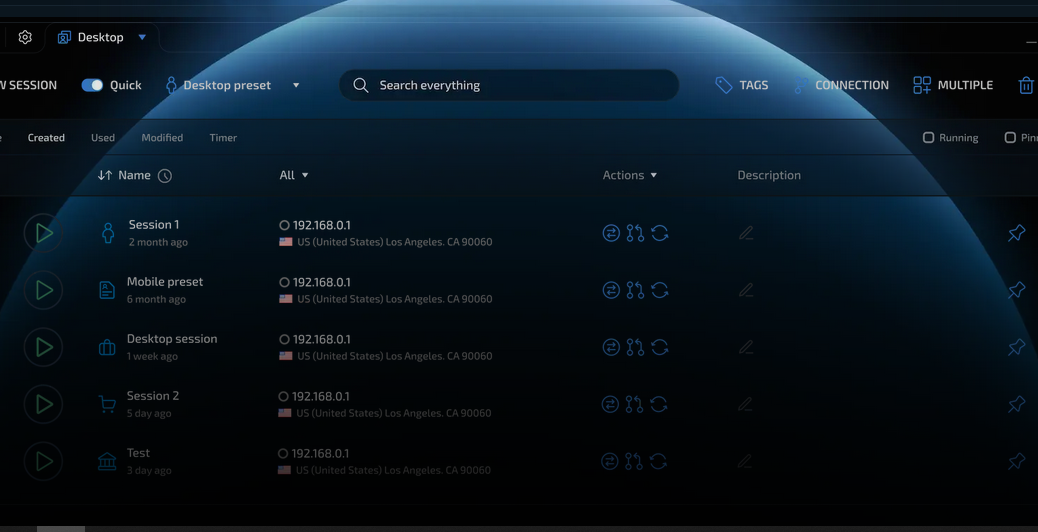
Mass data extraction, commonly referred to as web scraping, has become a critically important process for a vast array of modern business sectors. Marketing agencies relentlessly scrape competitor websites to analyze pricing strategies, human resources departments automatically harvest resumes from job boards, SEO analysts continuously monitor search engine result pages (SERPs), and e-commerce platforms track real-time inventory levels across global supply chains. However, website owners are acutely aware of the tremendous value of their proprietary data and actively deploy formidable defenses to protect their resources from automated queries. The widespread adoption of intelligent, AI-driven bot protection systems such as Cloudflare Turnstile, DataDome, and Akamai has transformed classic web scraping into a highly complex, resource-intensive battle. These security servers instantaneously block IP addresses originating from known data centers and serve endless loops of unsolvable CAPTCHA challenges to suspicious traffic. To bypass these severe technical limitations, developers are increasingly turning to advanced solutions. By utilizing a professional antidetect browser, automation scripts can be disguised to look exactly like ordinary, living website visitors.
The Inadequacy of Traditional Scraping Tools
Modern anti-bot systems utilize a holistic, multi-layered approach to evaluate every single incoming HTTP request. When a script attempts to access a protected webpage, the server analyzes much more than just the standard HTTP headers. It actively attempts to execute complex JavaScript challenges on the client side to verify the environment. If the request originates from a standard programming library—such as cURL, Python’s Requests, or a basic headless Selenium instance—the security system immediately recognizes the complete absence of a legitimate browser environment. The request lacks a natural browsing history, there are no recorded mouse movements, and crucial hardware parameters like Canvas and WebGL either return null values or present hashes that are universally recognized signatures of headless browsers.
The first line of defense encountered is almost always a strict IP address reputation check. Requests originating from server-grade IP addresses (such as those owned by AWS, DigitalOcean, or Hetzner) are assigned a notoriously low Trust Score and are typically blocked outright. The second, much more difficult barrier is the evaluation of the device’s digital footprint (fingerprint). Protective algorithms probe the browser for specific details regarding the graphics card, installed system fonts, screen resolution, and active plugins. If the scraping script is incapable of intelligently and realistically spoofing these parameters, the target website will simply return a 403 Forbidden error or present an insurmountable CAPTCHA. Under these hostile conditions, scraping even a few thousand pages devolves into a constant, exhausting struggle against IP bans and connection timeouts.
Emulating Authentic Environments for Data Extraction
For automated scripts to function stably and continuously, they must be executed within an environment that flawlessly mimics a real, physical computer operated by a human being. Enterprise-grade software allows developers to generate hundreds of virtual containers, each possessing a unique yet absolutely realistic digital footprint. From the perspective of a sophisticated security system like Cloudflare, the incoming request appears to originate from an ordinary consumer sitting at a home laptop running a standard installation of Windows 11 with the most recent version of a Chromium-based browser.
To execute large-scale scraping operations, developers create vast pools of these isolated profiles. The software automatically handles the complex task of spoofing graphics rendering parameters, WebGL, AudioContext, and media device inputs at the browser kernel level. When these perfectly crafted profiles are combined with high-quality residential or 4G mobile proxy servers, every single request sent to the target website is granted the highest possible Trust Score. The server registers a residential IP address, properly formatted headers, and a completely natural hardware footprint. Consequently, the protective systems allow these requests to pass seamlessly without triggering any CAPTCHA challenges, which exponentially increases the speed of data collection and entirely eliminates the recurring costs associated with third-party CAPTCHA-solving services.
Integrating with Developer Automation Frameworks
A pivotal advantage of modern secure environments is their native ability to facilitate seamless integration through robust APIs with popular automation frameworks, such as Puppeteer, Playwright, and Selenium. Developers no longer need to waste weeks trying to engineer custom patches to bypass headless mode detection or manually fix WebDriver leaks. All the heavy lifting associated with masking the automation framework and spoofing system characteristics is handled silently “under the hood” by the browser’s modified core engine.
The automated script simply connects to an already running, highly unique profile via the remote debugging protocol. This elegant architecture enables the implementation of incredibly complex behavioral scenarios. Developers can easily program the script to simulate randomized human clicks, execute natural page scrolling with variable speeds, and fill out complex web forms with artificial, human-like delays between keystrokes. This sophisticated approach unlocks limitless possibilities for scaling business operations. Reliable automation of routine tasks drastically reduces the operational load on the engineering team, completely eliminates human error, and ensures the continuous, uninterrupted flow of critical data from even the most heavily fortified platforms on the internet, all without the slightest risk of blacklisting.
Benzer İçerikler
![PowerPoint Sunumlarını Yapay Zekayla Profesyonel Videolara Dönüştürün]()
PowerPoint Sunumlarını Yapay Zekayla Profesyonel Videolara Dönüştürün
![Hide Expert VPN – Reliable Protection of Personal Data Online]()
Hide Expert VPN – Reliable Protection of Personal Data Online
![En İyi VDS Firmaları (2026) – Güvenilir Sanal Sunucu Sağlayıcısı Verigom]()
En İyi VDS Firmaları (2026) – Güvenilir Sanal Sunucu Sağlayıcısı Verigom
![Teknoloji Projeleri ve Dijital Dönüşüm: Toplumu Geleceğe Taşıyan Girişimler]()
Teknoloji Projeleri ve Dijital Dönüşüm: Toplumu Geleceğe Taşıyan Girişimler
![Контекстная реклама как инструмент быстрого привлечения клиентов]()
Контекстная реклама как инструмент быстрого привлечения клиентов
![İnternette Gerçek Hızı Yaşamak İsteyenler İçin En Doğru Tercih]()
İnternette Gerçek Hızı Yaşamak İsteyenler İçin En Doğru Tercih
![FlexClip’in Yeni Yapay Zeka Özellikleri: AI Recreate ve Auto Edit]()
FlexClip’in Yeni Yapay Zeka Özellikleri: AI Recreate ve Auto Edit
![How to open a profitable VR Business: From idea to implementation]()
How to open a profitable VR Business: From idea to implementation
![X (Twitter) ve Threads Videolarını İndirme Rehberi]()
X (Twitter) ve Threads Videolarını İndirme Rehberi
![Что такое французский поцелуй и почему он считается искусством страсти]()
Что такое французский поцелуй и почему он считается искусством страсти











